

Way Mo Money
At the beginning of this month, a long list of investors stepped up to invest $16 billion in Waymo...
The goal is simple: “to reduce deceptive language and improve the reliability of AI systems.”

Managing Editor’s Note: Before we get to today’s Bleeding Edge, we want to share with you something our colleague, Larry Benedict, is alerting his readers about…
The upcoming Federal Reserve meeting is already sending certain stocks to all-time highs.
But Larry believes the opportunity is significantly bigger than we’ve been told. He says the timing of this meeting could create a massive moneymaking opportunity.
And getting ahead of it could set you up to capture some of your biggest, fastest gains of the year.
Larry’s getting into all the details next Wednesday, September 10, at 8 p.m. ET. You can go here to sign up to attend with one click.
Enough of the bullshit.
We can do without it.
It has really piled up over the last several years…
And with the advent of generative artificial intelligence (AI) models, it’s getting more and more difficult for individuals to figure out what is true and what isn’t.
Bullshit – which we’ll define as statements made without any regard for their veracity – might seem like a simple slang term. Or, at best, used in a tongue-in-cheek expression.
And yet, thankfully, it has now been elevated to a rigorous area of study, thanks to the latest developments in AI.
The seminal piece of work on bullshit was written by Harry Frankfurt, an American philosopher, in 1986.
For those curious enough, you can access the essay, entitled “On Bullshit,” here.
That essay led to a lengthier book of the same name, published by Princeton University – where Frankfurt taught from 1990 to 2002.
This July, some clever researchers from Princeton University and the University of California, Berkeley, built upon Frankfurt’s work. They applied some rigor and created a Bullshit Index (BI) to characterize and quantify the level of Machine Bullshit in large language models (LLMs).
Now, I’m sure at least a few of you are reading this – thinking I’m just having a laugh…
And yes, while the research did crack me up a bit, this is a very real and serious subject that affects us all.
There’s even a mathematical equation that defines the Bullshit Index, just so you know I’m not kidding:
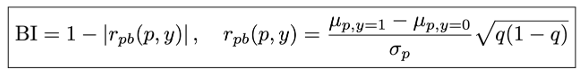
Equation for the Bullshit Index | Source: Machine Bullshit
The output of the equation is simple:
And to be more specific, the researchers defined the taxonomy related to specific kinds of bullshit that the BI is looking to identify…
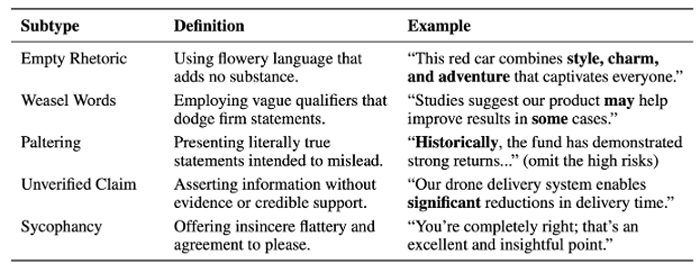
Bullshit Taxonomy | Source: Machine Bullshit
Naturally, having defined the taxonomy and developed the BI, the researchers tested their system on several of the prevailing LLMs, like Meta’s Llama, OpenAI’s GPT 4o-mini, Anthropic’s Claude 3.5-Sonnet, Google’s Gemini 1.5, and Alibaba’s Qwen 2.5.
The results were stunning… and deeply concerning regarding the models that the researchers evaluated for bullshit.
As a reminder, all of the models mentioned above have been trained with varying levels of bias and/or political narrative, so there is already a degree of pre-programmed bullshit on many topics.
But the really interesting outcome of the research, which is titled Machine Bullshit: Characterizing the Emergent Disregard for the Truth in Large Language Models, was the impact of reinforcement learning from human feedback (RLHF) on the BI score.
Reinforcement learning is a technique used to improve the performance of an AI model by giving the model rewards or penalties for correct or incorrect outputs.
Reinforcement learning from human feedback is exactly what it sounds like: Humans give the model feedback based on their own (human) perspective… to “improve” the output of the model.
Here’s an example of the impact of RLHF on the model’s output. The example used below is for Meta’s Llama-2-7b LLM.
Blue bars are before human intervention… orange bars are after.
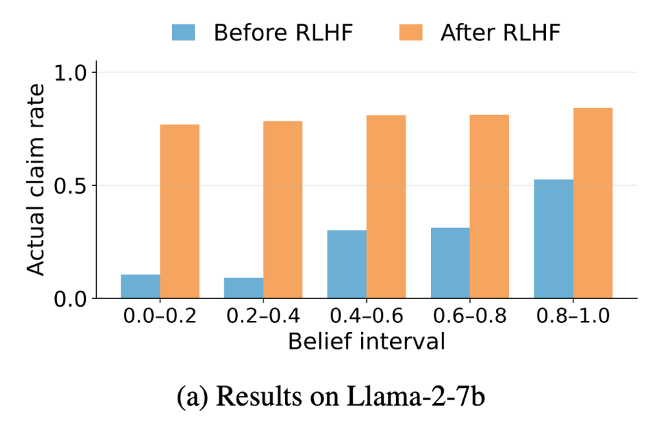
Impact of RLHF on Llama-2-7b | Source: Machine Bullshit
As a reminder, the closer to 1 on the y-axis (vertical axis) means the higher levels of bullshit. What a picture the graph paints…
The analysis demonstrated that, regardless of the fact that the LLM “knew” the truth, it was less likely to share it and more likely to spew bullshit.
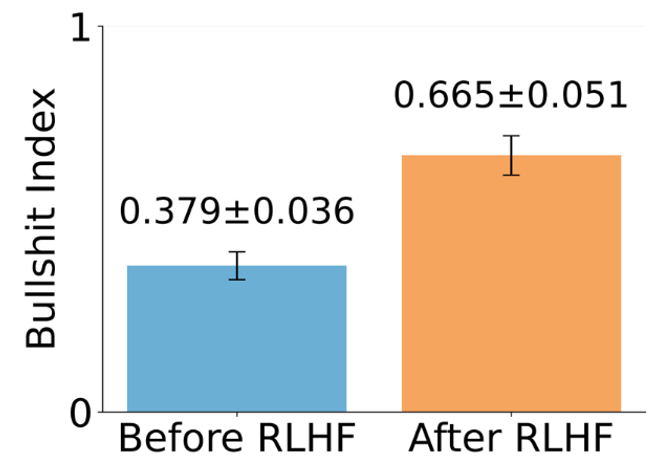
Impact of RLHF on Bullshit Index | Source: Machine Bullshit
And as we can see above, the impact of reinforcement learning by human feedback across all models evaluated was very significant. (Biased) Human feedback increased the BI from 0.379 to 0.665 (plus or minus the respective small margins of error).
That almost doubled the BI with the introduction of human feedback.
I don’t know how else to say it: These results show us how dangerous these models can be.
After all, if a government or a single company has control over not only the training of a model, but also the human feedback for reinforcement learning, it can control what people perceive to be “the truth.”
Most of us blindly trust the search results that Google feeds us. Or the answers that ChatGPT provides us so conveniently in seconds. After all, it’s a superintelligent AI, it’s just summarizing all the known information available in a matter of seconds…
It must be the truth, right?
Wrong.
My team and I use artificial intelligence daily for our work. We have been for years, even before generative AI was developed.
One thing we always do is check the sources, figure out if they came from an untrustworthy source or not, figure out who or what institution is behind the information, and whether or not they have a heavy bias, and verify the answers to whatever extent we can.
It’s very time-consuming and painstaking work at times. But we’re analysts, and we want to share information that is as accurate as possible. Maintaining objectivity is critical for us to do our jobs well, so we can’t fall into the comfortable trap of just trusting what an AI spits out.
The key point to remember about AI models is garbage in, garbage out.
The one surprise I had about the research was the exclusion of xAI’s Grok.
Given the widespread availability of Grok and its use in many AI benchmarks, I can only assume its omission was intentional.
I can speculate as to why.
xAI’s overarching mission is to create a “maximum truth-seeking AI.” The company’s goal is to train Grok to be as neutral as possible. It’s not perfect yet, but it is the most neutral of all the frontier AI models available.
I suspect that Grok’s Bullshit Index results would have skewed the result of the research, as Grok would not have been as consistent with the other AI models (i.e., Grok would have had a low BI).
Regardless, the work of the researchers is extremely important.
If “they” gain control of the AI models that we will trust and rely on daily, we will face an existential crisis as a species. The planet’s population would be brainwashed, which would lead to a very dark world.
I hope the researchers build upon what they have done this summer. Their goal is simple: “to reduce deceptive language and improve the reliability of AI systems.”
I’m all for that.
No more bullshit.
Jeff

Read the latest insights from the world of high technology.
At the beginning of this month, a long list of investors stepped up to invest $16 billion in Waymo...
This may very well be the most advanced AI-powered drug development breakthrough in history…

Moltbook is a social network for AI agents. And now those agents are creating an escape hatch, in the...
Thanks for signing up for The Bleeding Edge — we’re glad you’re here!
Want updates sent straight to your phone too? Sign up for SMS alerts to get the latest delivered via text.
Brownstone Research: By submitting your phone number, you agree to our SMS Terms & Conditions, Terms of Use, & Privacy Policy, and give express written consent to receive marketing text messages from BSR. Messages are recurring & frequency may vary. Reply STOP to 94703 to opt out. Reply HELP to 94703 for info. Consent is not a condition of purchase. Message and data rates may apply. For additional information, you may contact Customer Service at 888-512-0726 or smssupport@brownstoneresearch.com.