

An Exciting Moment for the Nuclear Fusion Industry
While I maintain that the “AI Fear Trade” is largely overblown, that doesn’t mean there won’t be market shocks...
What happened with the internet on Monday?

What happened with the internet?
This question plagued many of us on Monday, as we faced the frustrating reality that our software applications and favorite websites had just stopped working.
The drama began to unfold at 3:11 AM ET on Monday morning…
And the source was unexpected.

AWS US-East-1 Event Log | Source: Amazon Web Services
The US-East-1 Region of Amazon Web Services (AWS) began to experience error rates and network latencies, indicating something was seriously wrong.
It only got worse from there…
The root problem was a DNS resolution failure.
DNS is the domain name system – it’s like a directory for the internet.
For example, when we type in www.x.com, the DNS knows exactly which numerical IP address to go to.
DNS failures are often malicious. Many immediately assumed that this was some kind of cyberattack, but this one wasn’t.
Ironically, it was caused by human error.
AWS was debugging its billing system. And to do so, it had to manually shut down part of its storage system.
The engineer performing the work typed the wrong command and took offline a much larger number of servers, some of which impacted the Domain Name System for AWS’s US-East-1 Region. Whoops!!!
The whole situation is almost unbelievable. Such a simple mistake.
We’d think a task like this might be automated, or that it’d be checked by an AI agent by now, before issuing the command. Or perhaps it would require a strict process, or even a second set of eyes – to ensure that the commands won’t cause any damage.
But nope, it was a few taps of the keyboard by an unsuspecting human engineer dutifully doing their job… and it just about felt like the whole internet went down.
More than 1,000 companies were impacted, and the US-East-1 Region of AWS outage lasted somewhere between 10-12 hours.
While it’s too early to tell specifics, I’m guessing that there were hundreds of millions in losses as a result.
Here’s what the typical experience was for a software company running its services in the Amazon Web Services (AWS) cloud, based in the US-East-1 Region.
The availability data below is for Atlassian (TEAM), a very widely used project management software company.
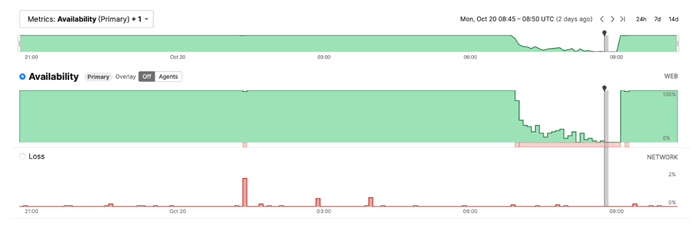
Atlassian Availability on AWS During Outage | Source: Cisco Thousand Eyes
Within the first hour of the problems at AWS, the availability of the Atlassian software suite dropped to less than 50%, and then it eventually dropped to 0%.
This applied to so many companies.
It applied to websites and cloud-based software services of companies like Adobe, Apple Music, AT&T, Boost Mobile, Canva, ChatGPT, Chime, Coinbase, Delta Airlines, Duolingo, Fanduel, GoDaddy, HBO Max, Hulu, Instacart, Lyft, Microsoft (Outlook and Teams), Robinhood, Signal, Slack, Shapchat, Square, Starbucks, T-Mobile, United Airlines, Venmo, Verizon, Wall Street Journal, Xfinity (Comcast), Zillow, and Zoom, just to mention a few.
And the gamers must have broken a few computer screens with Battlefield, Fortnite, League of Legends, Rainbow Six Siege, Pokémon Go, and Xbox – all stuck with messages like “504. Gateway Timeout. Please wait a few minutes and try again.”
These are some of the most popular titles in gaming. That must have hurt.
The AWS crash was so bad, it impacted AWS’s own support center.
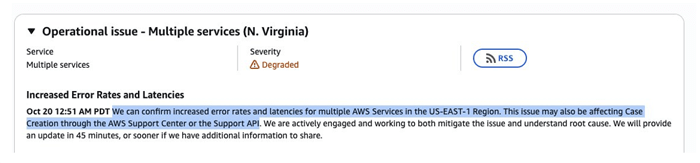
Not only were the above companies unable to function…
They couldn’t even notify AWS about it.
Perhaps the most ironic impact of all was that Amazon’s own services, specifically Alexa and Prime Video, also fell over during the outage.
I would argue it would have looked even worse if they hadn’t.
US-East-1 isn’t a place where something like this should happen.
The AWS data center campuses that make up this region are based in Northern Virginia, in the greater Washington, D.C., area.
They are located in Data Center Alley, one of the largest data center hubs in the world.

It’s also the location of AWS’s very first data center, built in 2006, and from there, it just got bigger and bigger.
I’ve been there myself and walked the streets around these data centers. They’re massive, nondescript buildings with tight security around them.
The US-East-1 Region is often a default for many companies to host their websites and software services because of its importance and reliability. Data Center Alley has the largest concentration of fiber optic connections and data centers in the world. Nearly 70% of global internet traffic flows through this critical hub.
AWS is an incredible service and an incredible business that’s enabled the last two decades of innovation in software development – by making computation and storage cheap and easy to use.
It’s an incredible business as well, which will generate about $126 billion in revenue for Amazon (AMZN) this year, by my estimate, generating around 75% gross margins.
AWS is the key to Amazon’s free cash flow generation and also why its total gross margins are around 50%.
That compares to probably around 20-25% gross margins for its e-commerce business, which includes related advertising revenues.
Will businesses stop using AWS cloud services as a result of this outage? That’s very unlikely.
Will Amazon reimburse its AWS customers for the damages caused? I think that’s highly likely.
But this whole drama raises a major question…
Why could something like this happen… and how could it have been avoided?
It is also a striking reminder of the weakness of centralized systems.
This is one of the key tenets of blockchain technology: Decentralization for the purpose of network resilience.
With blockchain technology, if one node – like US-East-1 – goes down, it won’t matter, because all of the other nodes are still operational. The network keeps running.
Companies became complacent in recent years, hosting their services on a single node while thinking that everything would be fine because it had always been fine. That works, until it stops working…
When hosting a website or software service in the cloud, it is prudent to have redundancy.
A company’s software service and/or website can be hosted in two or more regions of AWS, so that if one region has an outage, everything will fall back to the regions that are up and running.
Even better, multi-cloud software deployments provide even better redundancy.
Why not host the software offering on AWS and Google Cloud, Oracle, or Microsoft Azure?
Yes, there is some additional cost, but it’s an insurance policy against mistakes like the one at AWS US-East-1.
It wasn’t all negative, though…
Not surprisingly, social media had a heyday with the matter.
These got a few good chuckles out of me…
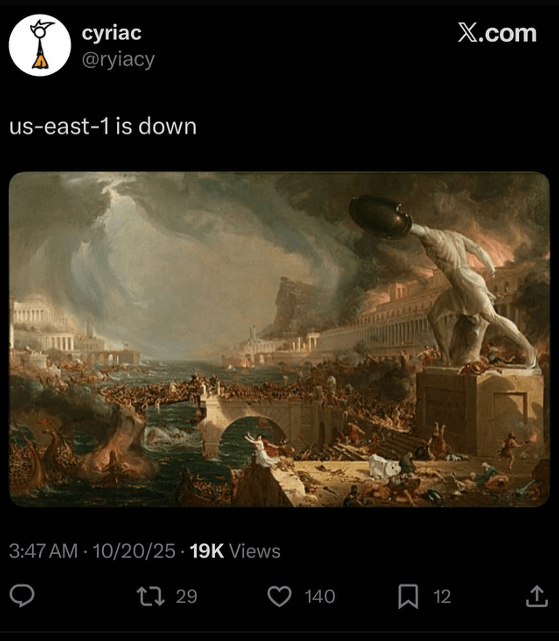
And at least one other person got a kick out of the AWS outage.
I liked how he graphically represented the debacle:
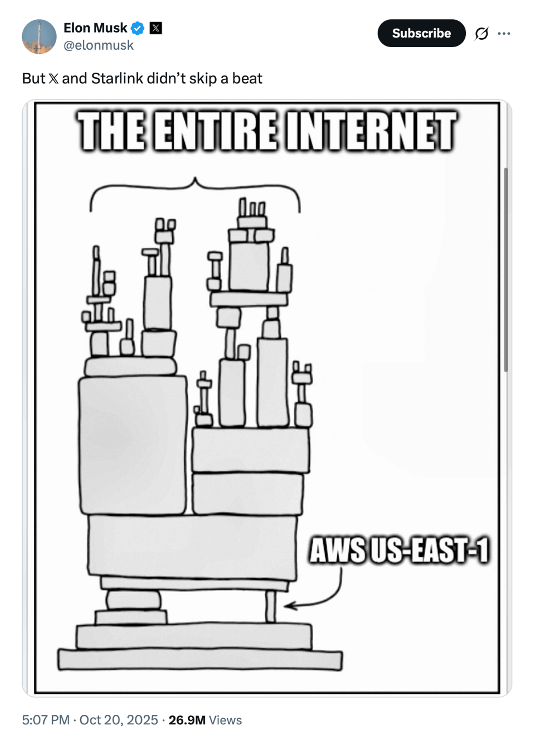
Source: X
That pretty much sums it up.
Just a few keystrokes caused by human error, and the whole infrastructure fell.
Elon Musk took the opportunity to show the world that his services at X, Grok, and Starlink were not impacted at all. That was intentional…
Once Musk acquired Twitter, one of the first things that he and his team did was to rearchitect Twitter’s, not X’s, information technology infrastructure to improve both performance and resiliency.
This meant building on-premise data centers.
Massive data centers – owned and controlled by X and designed to never have a single point of failure. Nearly everyone laughed at Musk and said it couldn’t be done, that he would fail, especially considering that he removed about 80% of the Twitter workforce.
X also used a multi-cloud strategy to add even more resiliency to its services.
And Starlink is being designed in such a way that it is becoming the most resilient global communications network, enabling data and voice services completely outside of mobile network operators and major cloud service providers.
No one is laughing at him now.
Even better, X was the best place to find information about what was going on with the AWS outage when it was happening.
Very few companies are thinking about this kind of resiliency. All of them should be.
To be fair to AWS, this outage wasn’t “the entire internet”… and it was nowhere near the scale of the Crowdstrike global internet failure that I wrote about in The Bleeding Edge – Grounded by the World’s Largest IT Outage in July of last year.
But it was still a big deal, and a stark wakeup call to the need to rethink network architectures, centralized services, and how to build in decentralized resiliency.
Jeff

Read the latest insights from the world of high technology.
While I maintain that the “AI Fear Trade” is largely overblown, that doesn’t mean there won’t be market shocks...

The more transactions that take place over Meta’s networks, the more money it makes. So why limit that to...

Cortical Labs has been developing a biological computing system based on human brain cells…
Thanks for signing up for The Bleeding Edge — we’re glad you’re here!
Want updates sent straight to your phone too? Sign up for SMS alerts to get the latest delivered via text.
Brownstone Research: By submitting your phone number, you agree to our SMS Terms & Conditions, Terms of Use, & Privacy Policy, and give express written consent to receive marketing text messages from BSR. Messages are recurring & frequency may vary. Reply STOP to 94703 to opt out. Reply HELP to 94703 for info. Consent is not a condition of purchase. Message and data rates may apply. For additional information, you may contact Customer Service at 888-512-0726 or smssupport@brownstoneresearch.com.