

Leveraging AI for Personalized Cancer Therapies
Someone with no medical training whatsoever leveraged AI to devise a custom cancer vaccine entirely on their own, in...
Last week’s release of OpenAI’s most recent frontier AI model, GPT-5, didn’t go as planned…

It was supposed to leap ahead of the rest of the industry.
Designed to be a unified model, it combined the best capabilities of all prior models…
But for OpenAI and the release of its most recent frontier AI model, GPT-5, last week, things didn’t go as planned.
In one fell swoop, OpenAI removed access to eight previous AI models that provided incredible utility to millions around the world. OpenAI then replaced them all with GPT-5, expecting rave reviews.
Sadly, that’s not what happened.
We can discount all the criticisms from the tech community about how uninspiring the GPT-5 announcement and livestream were.
After all, the expectations are so high right now for the next AI breakthrough, and not every product announcement can be like Steve Jobs’ first product release of the iPhone.
But OpenAI didn’t do itself any favors.
Just have a look at this beauty of a chart below, from the livestream:
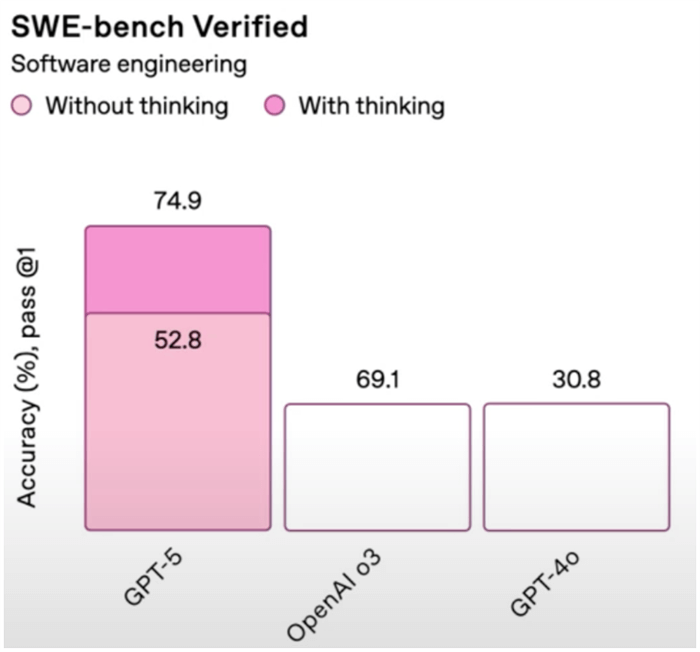
Source: OpenAI
If we take a close look at the numbers – specifically the high number of each bar – none of it makes sense.
Model o3 has a score of 69.1, and model o4 has a score of 30.8. So why are the bars the same height?
And GPT-5 “without thinking” (the pale pink bar) has a score of 52.8. It’s a lesser number, but why is the bar a lot higher than o3’s score of 69.1?
Yikes. Obviously, a major screw up.
Earlier this year, OpenAI raised $40 billion and is now valued at $300 billion. Its resources and access to capital are nearly unlimited.
And yet, it can’t get a simple chart like the one above, right?
Of course, the chart has since been corrected on its website, but the damage is done… and confidence in OpenAI is withering.
This is a shame, because GPT-5 is still incredible technology, and it made notable improvements in mathematics, software coding, and science in particular.
GPT-5 finally scored a 100% on the AIME 2025 competition math benchmark using its GPT-5 pro version with Python.
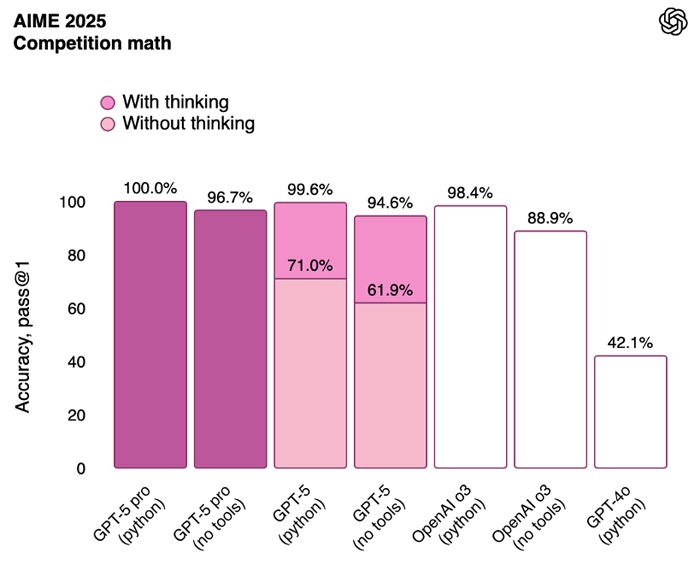
Source: OpenAI
It made notable improvements in software coding.
In the software coding benchmark, SWE-bench Verified, GPT-5 jumped from 69.1% to 74.9% compared to its previous best model.
And in the Aider Polyglot Multi-language code editing benchmark shown below, it improved to 88% “with thinking.”
As a reminder, “thinking” in these frontier AI models is giving the AI model additional computational resources to “think” and reason in order to improve performance.
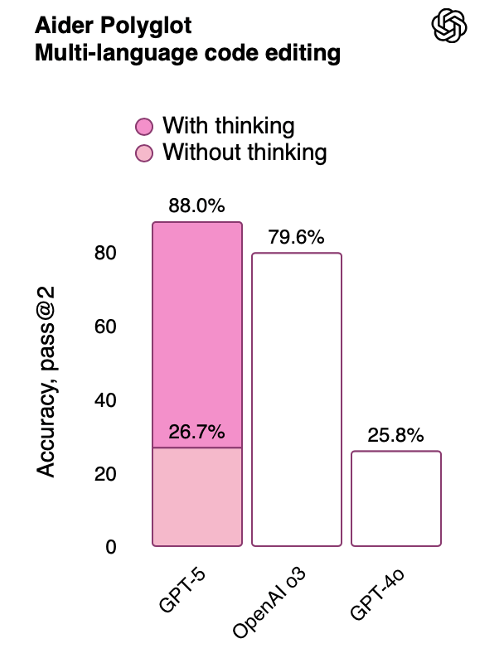
Source: OpenAI
And the PhD-level scientific benchmark GPQA Diamond saw an improvement in performance to 89.4%.
This is still impressive, considering the questions asked in the GPQA Diamond can’t be answered by a Google search. Human PhDs struggle with these questions, some of which can take hours to answer a single one.
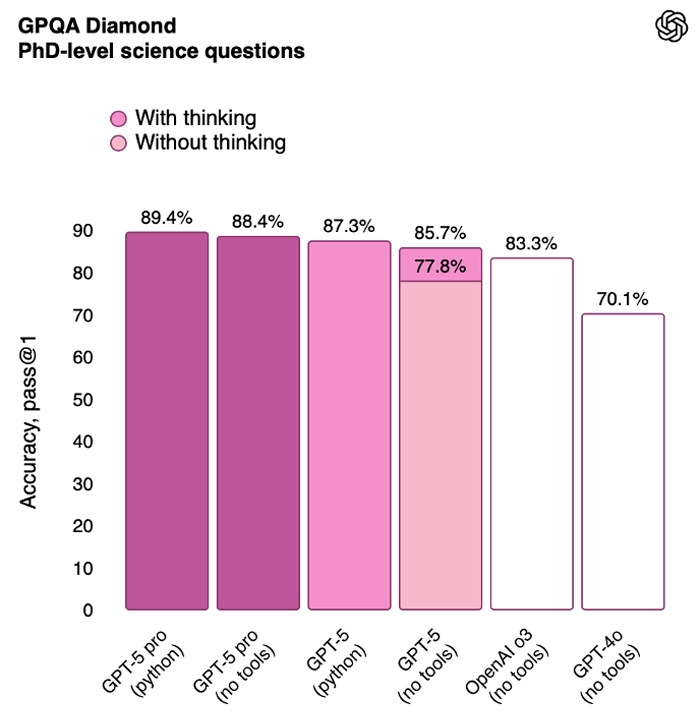
Source: OpenAI
But despite the improvements, many of OpenAI’s avid users would have none of it.
Reddit channels have been on fire with complaints about the model.
One example below pretty much sums up the sentiment.

Source: Reddit
It was ugly. I haven’t seen that much negativity about a product release in some time.
It got so bad that on Friday, OpenAI’s CEO, Sam Altman, announced that they would reinstate the earlier model GPT-4o to its ChatGPT Plus subscribers.
But while the industry and OpenAI’s users were caught up in their disappointment with the unified model GPT-5 – and what they believed to be worse performance and a much less desirable communication style – I was focused on two metrics in particular that are centered around artificial general intelligence (AGI).
The first benchmark was Humanity’s Last Exam, an extremely complex benchmark with 2,500 questions that require expert-level intelligence on a wide range of topics.
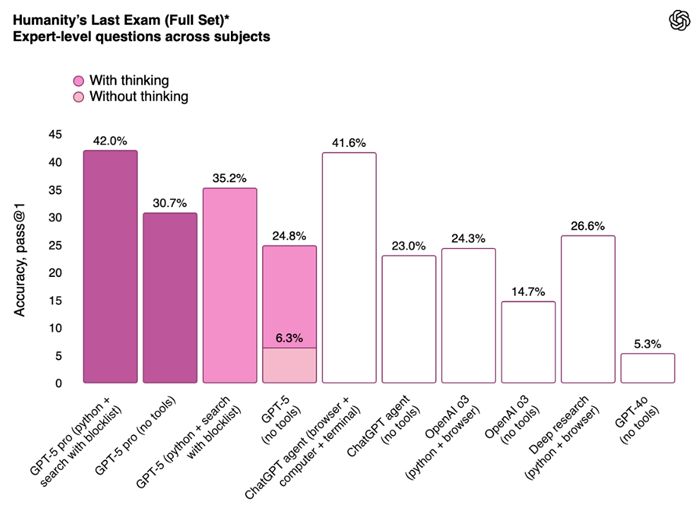
GPT-5 Performance on Humanity’s Last Exam | Source: OpenAI
And while GPT-5 showed a large improvement at 42% compared to o3 and GPT-4o, it was a long way from xAI’s Grok 4, which scored 50.7% when given time to train.
And the second benchmark is the ARC-AGI-2 benchmark, an even more difficult test of general intelligence.
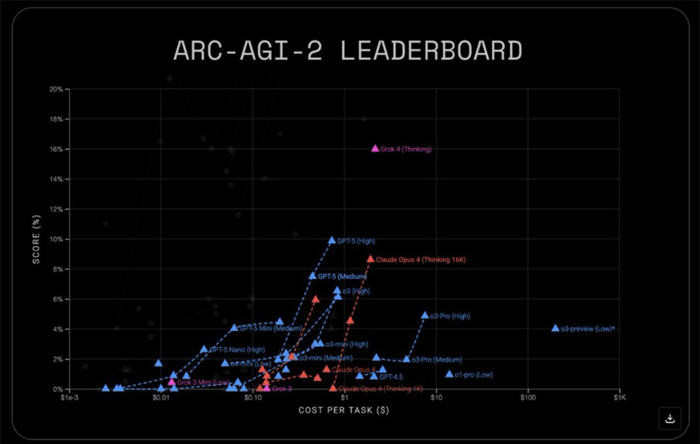
OpenAI’s GPT-5 came in at 9.9%, well behind Grok 4, which scored 16% on its release in early July.
It’s over. xAI has broken out of the pack. Grok 4 was released more than a month ago, and OpenAI’s latest simply isn’t good enough. And as I predicted in March this year, xAI will win the race to AGI.
As I said in The Bleeding Edge – The Everything App on March 31:
xAI will become the first company in the world to develop an artificial general intelligence (AGI), and it will happen within 12 months.
OpenAI’s inability to leapfrog xAI with its latest release is telling. For the last two years, that’s typically what happened with every major release from one of the major players in frontier models, namely OpenAI, Anthropic, Google, Meta, and then suddenly xAI.
OpenAI and the others simply can’t keep up with Musk and his team at xAI. They can’t match the technology or the pace of innovation of xAI.
Love him or hate him, Musk and xAI are untouchable. I explained why in March…
xAI takes an optimized approach with its neural network design using a mixture of experts, sparse attention mechanisms, and recurrent neural networks to improve both efficiency and memory retention.
In addition to that, xAI uses reinforcement learning to improve its performance based on user interactions. Grok is also capable of online learning. As it receives inquiries, it can access the latest information and update its parameters. It’s “learning,” in near real-time.
This architectural approach enables Grok to rapidly adapt and improve almost daily.
The second reason is that no other company in the world has been able to assemble and commission hundreds and thousands of GPUs as quickly as xAI.
xAI’s goal is to get to 1 million GPUs by the end of the year. Whether it’s 800K or 1 million, it doesn’t matter. It will be multiples of the 200,000 GPUs that Grok 3 was developed on.
xAI now has 230,000 GPUs running at its Colossus 1 data center in South Memphis, and about 100,000 GPUs already commissioned at its nearby Colossus 2 data center.
And Colossus 2 is being built in real time to support 550,000 GPUs.
At the current pace, achieving 800,000 GPUs by December in the combined facilities is on track, something thought to be impossible by most.
So when Musk makes a statement like the one below, it’s not blustering or hyperbole. It’s based on concrete progress.
Source: X @elonmusk
Grok 4 continues to improve every week, and that’s for the reasons I stated above in my March issue of The Bleeding Edge. Will Grok 5 be the breakthrough in AGI that the industry has been chasing?
Some will certainly make that claim, but to answer that will depend on how AGI is defined. It will appear to be so to most people using Grok 5.
OpenAI itself defines AGI as…
A highly autonomous system that outperforms humans at most economically valuable work.
But whether it is a more general definition like the one shown above, or the ability to perform well on Humanity’s Last Exam or the ARC-AGI-2 benchmarks, Grok 5 is going to be very close.
And no later than March 31, 2026. I stand by my prediction…
xAI will claim the prize – first to achieve AGI.
Jeff

Read the latest insights from the world of high technology.
Someone with no medical training whatsoever leveraged AI to devise a custom cancer vaccine entirely on their own, in...

If NVIDIA hits the scale Jensen Huang is signaling, we’re no longer talking about incremental growth in data center...

When Elon Musk stated he wanted to build his own semiconductor manufacturing plant, many assumed he was just bluffing…
Thanks for signing up for The Bleeding Edge — we’re glad you’re here!
Want updates sent straight to your phone too? Sign up for SMS alerts to get the latest delivered via text.
Brownstone Research: By submitting your phone number, you agree to our SMS Terms & Conditions, Terms of Use, & Privacy Policy, and give express written consent to receive marketing text messages from BSR. Messages are recurring & frequency may vary. Reply STOP to 94703 to opt out. Reply HELP to 94703 for info. Consent is not a condition of purchase. Message and data rates may apply. For additional information, you may contact Customer Service at 888-512-0726 or smssupport@brownstoneresearch.com.