


Will Musk Turn to Small Modular Reactors?
There has certainly been no shortage of excitement in growth assets and the tech industry…
The biggest announcement of the week was about Google’s 8th generation of its TPUs, short for Tensor Processing Units.

Google (GOOGL) is in Las Vegas this week, holding its annual Google Cloud Next confab.
This is the company’s annual conference for its Google Cloud division, which is responsible for its cloud services offerings.
More than a decade ago, Google – the industry’s leading internet search and advertising company – got caught flat-footed by Amazon in offering cloud-based computation and storage to anyone wanting to lease it.
Amazon transformed the entire information technology industry by lowering the costs of compute and storage dramatically, enabling companies to simply use Amazon Web Services (AWS) rather than building their own in-house data centers.
Seeing Amazon’s (AMZN) great success with cloud services, Google raced to catch up.
Back in 2017, Google’s cloud services were just 3.6% of Google’s total revenues.
This year, Google Cloud will generate about 18% of Google’s revenues, climbing to about 25% by 2028 (forecasted).
Despite the contributions of Google Cloud, Google at its core remains an advertising tech company.
At least, that’s where it generates its free cash flows.
But over the last decade, machine learning – and now artificial intelligence, specifically neural networks – have reshaped the company’s underlying technology.
Not only is it used in its advertising business, but it’s also now used widely in search, its frontier AI models, and the amazing work out of Google’s DeepMind division, which has produced remarkable scientific discoveries that we’ve reviewed closely over the years in The Bleeding Edge.
It’s no surprise that this year’s Google Cloud Next conference is all about “The Future of AI Infrastructure.”
After all, Google’s hyperscale data centers are designed to provide the computational infrastructure for both the training of and running of artificial intelligence (AI) applications.
The biggest announcement of the week was about Google’s 8th generation of its TPUs, short for Tensor Processing Units.
These are AI-application-specific semiconductors that are custom-designed and optimized by Google, primarily for training and running its own AI models like Gemini.
Amin Vahdat, Chief Technologist for AI Infrastructure, Google Cloud | Source: Google Cloud
Over the last decade, large tech companies with widely deployed software applications began designing their own semiconductors that were optimized for their own software.
The alternative was to buy semiconductors off the shelf from other semiconductor companies…
But for a large enough tech company, the performance gains and efficiency improvements justified the research and development.
Google (GOOGL), Microsoft (MSFT), Meta (META), Tesla (TSLA), and SpaceX are all well-known tech giants that have pursued this path with great success.
And Google was one of the earliest to make the jump, as it was employing machine learning more than a decade ago in its own advertising technology.
Announced at Google Cloud Next are the Tensor Processor Unit (TPU) 8t and TPU 8i.
The small “t” stands for training, and the small “i” stands for inference.
Both products are designed to improve the efficiency and cost of training AI models and running AI models (i.e., inference).

Google’s TPU 8i | Source: Google
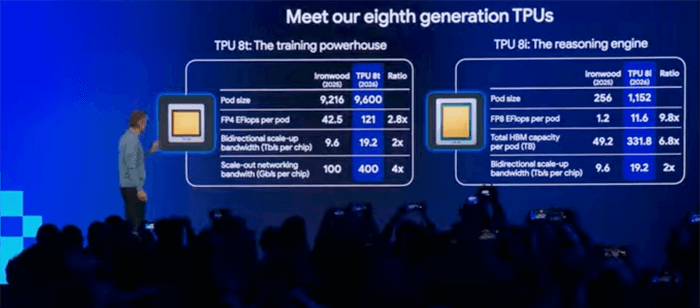
The TPU 8t for training is a significant step up in performance from the 7th-generation TPU, known as Ironwood.
A pod size is roughly the same – 9,600 TPU 8t semiconductors versus 9,216 for Ironwood.
But the performance of the pod is very different.
A TPU 8t pod runs an amazing 121 exaflops, almost 3X the performance of the last generation.
Bandwidth has more than doubled, and the networking throughput has increased by 4X.
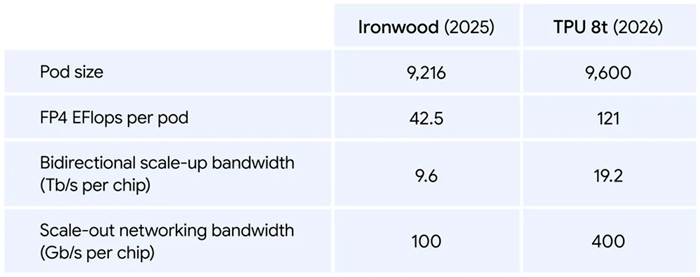
And while seemingly nuanced, the new TPU 8t are capable of a 10X improvement in accessing memory, which dramatically improves training times for AI models.
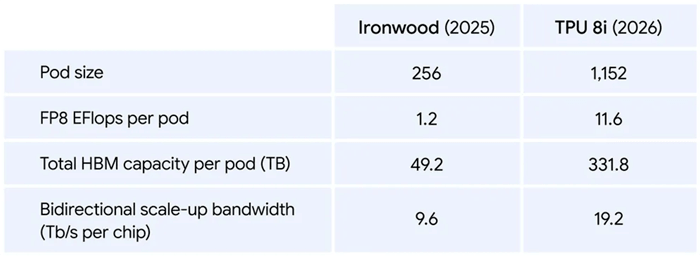
As for the TPU 8i which is designed for the running of AI applications, the performance differences are equally impressive from the previous TPU generation.
The pod size of TPU 8i has increased by 4.5X since last year, resulting in a 9.7X improvement in overall performance to 11.6 exaflops.
Total high-bandwidth memory (HBM) per pod has increased by 6.7X and bandwidth has also doubled.
Naturally, both the TPU 8t and TPU 8i have been designed for Google’s Gemini models…
But they can be used widely for a range of AI models and applications.
To many, it would appear that Google is attempting to encroach on NVIDIA and AMD’s stronghold on the GPU semiconductor market…
But it would be naïve to think this.
A TPU is optimized for tensor-heavy machine learning-type workloads and neural networks.
TPUs are ideally designed for large-scale AI workloads and applications with structured neural networks.
TPUs, like GPUs, are designed for parallel processing.
We can think of them as just being more specialized and less general-purpose.
That’s why I often refer to the GPUs from NVIDIA (NVDA) and Advanced Micro Devices (AMD) as the workhorses for artificial intelligence.
Not only are GPUs capable of what TPUs can support, but they can also easily handle graphics, video processing, video games, and complex simulations.
I often read from others that Google’s TPUs are a competitive threat to NVIDIA and AMD, but naïve and simplistic comments like that completely miss the point.
NVIDIA and AMD’s GPUs are excellent at handling mixed workloads and dynamic control flow, which is needed for most general-purpose computing.
The vast majority of the TPU utilization is happening by Google for Gemini-based applications and training.
Google Cloud’s AI data center infrastructure widely provisions GPUs for its cloud services customers.
TPUs are only part of its offering, as most cloud services customers run their AI payloads on GPUs for both training and inference.
The reality is that the size of the pie is expanding so rapidly that both TPU utilization and GPU utilization continue to grow at extraordinary rates.
It’s a bit odd to think of Google as a fabless semiconductor company, but its team that designs its TPUs represents exactly that.
And the winners are contract manufacturers like TSMC (TSM) and semiconductor equipment manufacturers like ASML (ASML), which are responsible for manufacturing Google’s semiconductors.
Google’s latest TPU announcement is positioned as “Infrastructure for the Agentic Era,” but what the team really wanted to say was “Infrastructure for the Artificial General Intelligence Era.”
The current generation of these semiconductors for both training and inference is so powerful…
And when combined with the latest generations of frontier AI models like Anthropic’s Claude Mythos, xAI’s Grok 4.3, Google’s Gemini, and OpenAI’s GPT 5.4, it just means that the AGI Era has already arrived.
AI models are already capable of general intelligence in any field, at or above the level of any human expert.
General intelligence is here. It’s just not widely distributed yet.
Read the latest insights from the world of high technology.
There has certainly been no shortage of excitement in growth assets and the tech industry…

There is another type of cage match playing out in Washington right now… The bare-knuckle fight between CFTC Chairman...

The biotechnology sector has shown clear signs of recovery over the past six months…